Lecture 03 Database Storage Part 1
课程视频托管在 YouTube 平台,如需观看,请确保您有访问 YouTube 的网络条件。
或者访问b站: F2023 #03 - Database Storage Part 1_哔哩哔哩_bilibili
我的视频:cmu15445 lecture 03 Database Storage Part1_哔哩哔哩_bilibili
Overview

不同层次将为数据库提供不同的功能和能力 公开一个API供上层组件使用
you're going to issue a SQL query and that's going to first show up and get parased, this the string of text of the SQL query gets parsed, you'll run through the query Optimizer below then we'll start executing whatever the query plan is. there'll be access methods that actually talk to the tables or indexes or whatever we're tring to access be a buffalo manager to manage the memory for our database system and then the lowest level will be a disk manager.
从application看起, 发出一个sql查询 首先会被显示并解析 (SQL查询文本字符串被解析) 我们将逐一介绍查询优化器 再次之下开始执行查询计划的内容 将会有访问方法来实际与table 和index 进行对话
然后存在一个缓冲池管理器来管理我们数据库系统的内存
在最底层 存在一个磁盘管理器负责数据的读写操作
我们假设的是构建一种 被称为基于磁盘的 数据库系统 或面向磁盘的架构
也就是说数据库管理系统会假设数据库的主要存储位置位于非易失性磁盘上 maybe a SSD or a spinning disk hard drive.
所以本质上我们要解决协调和编排数据在磁盘和内存之间的来回传输
Storage hierarchy
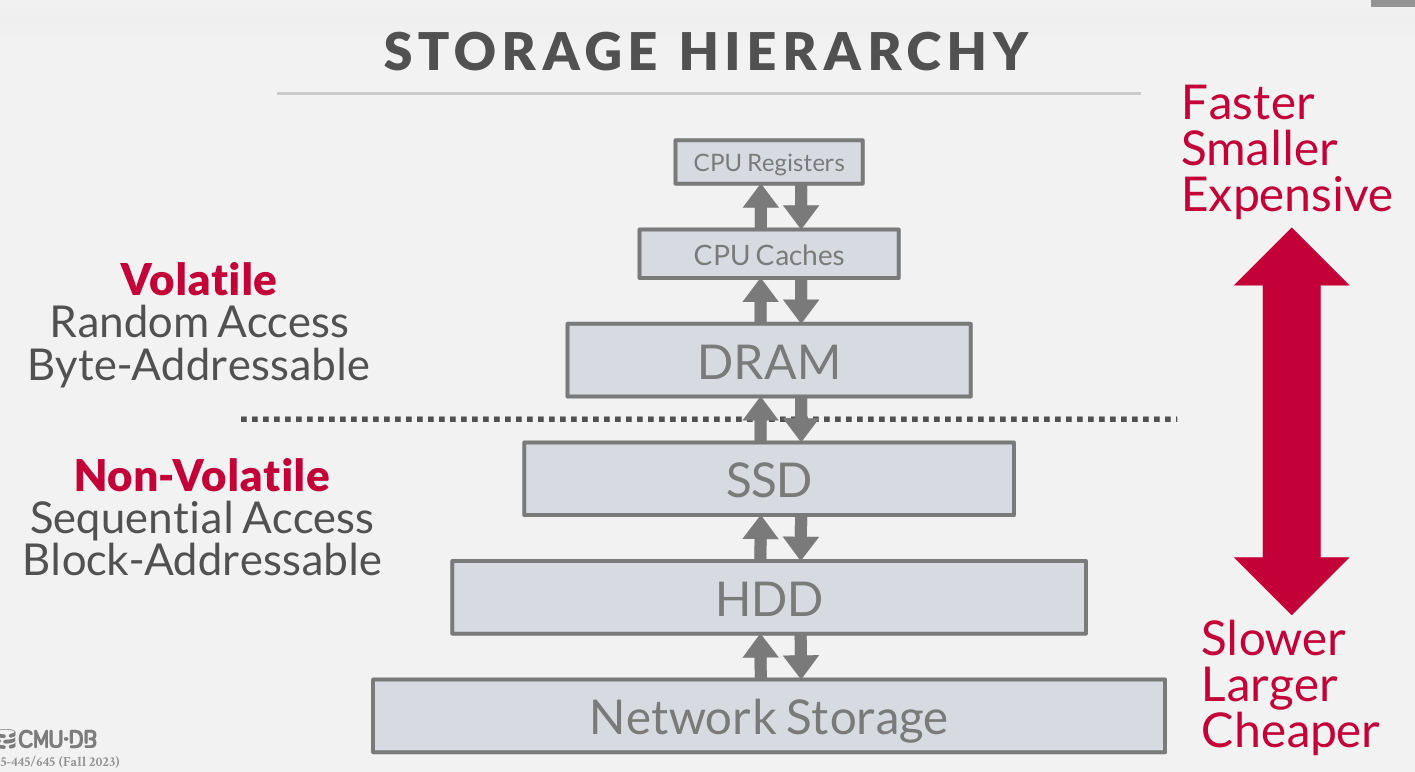
the only thing we care is the volatile and the non-volatile(易失性和非易失性)
in non-volatile, we can only fetching blocks, but the volatile considered to be byte addressable.
in non-volatile,we can only feching bolocks and bring that into memory and then do whatever you need.
易失性存储被视为是按字节寻址 但是 非易失性存储 只能将block放入内存 然后进行操作
SDD - 固态硬盘
HDD - 传统硬盘
we will chooose that'll maximize sequential access(最大化访问), ----其实就是用连续空间存
and something new
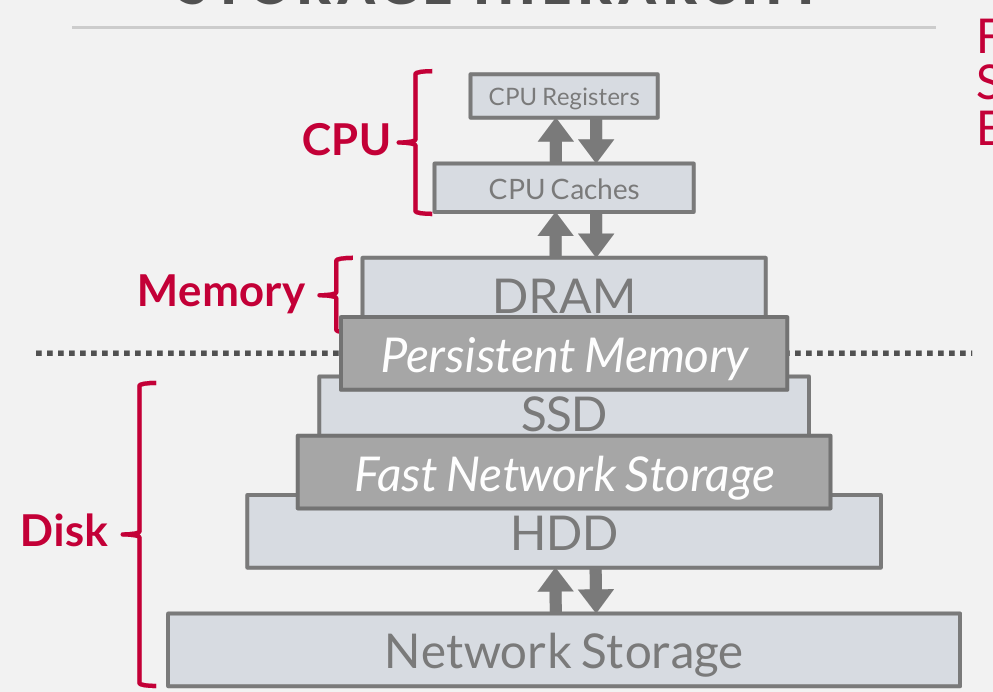
Intel Optane 傲腾 --- persistent memory 持久内存
这个东西可能会改变游戏规则 但是 Intel 新ceo cut it 因为 无法获利

sequential vs random access
database system is going to prefer sequential access over random access.
即使是在SSD上,由于其内部工作原理设计专用集成电路(ASICs) 以及数据压缩等操作 顺序批量读写仍然被认为是高效的做法
so the other system of design goals we're going to have and how we choose how we want to build our system uh is that we want to give the illusion that we're operating with the database entirely in memory. 我们关于系统设计的目标是我们希望营造一种假象—— 正在完全使用内存的方式操作数据库
it's look like virtual memory
so we don't want to do virtual memory for the OS
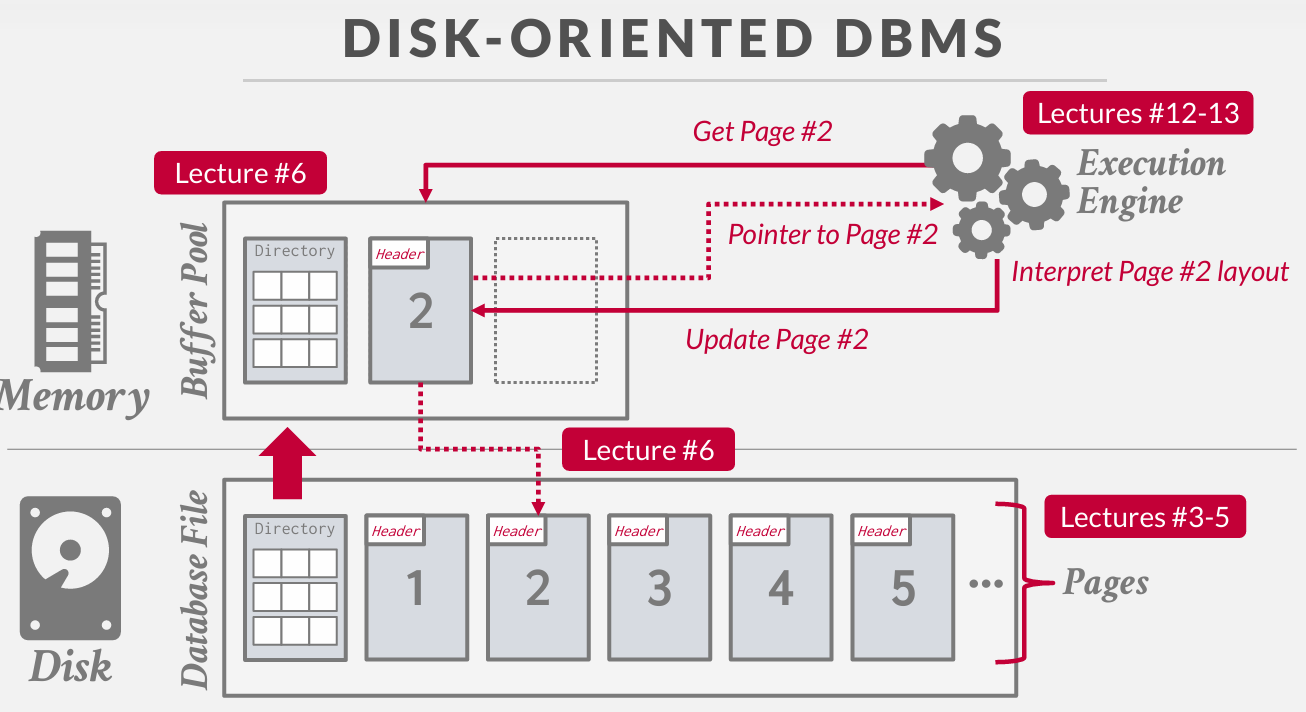
我们在Disk上有一些数据库文件----分成好多pages 还有 目录Directory--说明我有哪些页面--通过偏移量可以找到他们
we have some buffer pool ---- 缓冲池----其中的内存 数据系统分配基本上成为malloc
there'll be some buffer pool where of memory the data system allocated basically called malloc against the OS got some memory and then we're use that as the staging area where we bring pages in from disk. so now I have the execution engine(执行引擎). the thing that's going to run our query it comes along.
and It wants to get page number two,
- the first thing we're got to do is bring in the page directory because that's going to tell us where you know where on disk or the pages are.
- and then it'll make a call to the OS or whatever the divice it that's storing the database file and it'll bring that page into memory
- then the buffer pool will give back the execution engine a pointer in memory a 64-bit pointer in memory of where this page exists.
- and then the execution engine or the access method the operators to then interpret what's inside that page
- and then update
then back to disk
so why not use the OS?
the database system can use memory mapping(mmap) take the contens of a file that's on disk and you map it into virtual memory in your process 使得可以将磁盘中的文件内容映射到进程的虚拟内存中 即进程的地址空间内
and then that process can jump to any offset in that address space in memory 然后可以跳转到内存中改地址空间的任意偏移量处
and the OS is responsible for deciding is the thing you need in memory or not. if not, then it goes and fetches the page you need and brings it a memory.
so the database can't do any of the writes it just map opens the file and the OS does all the management of the data moving the data back and forth for us
look like this.
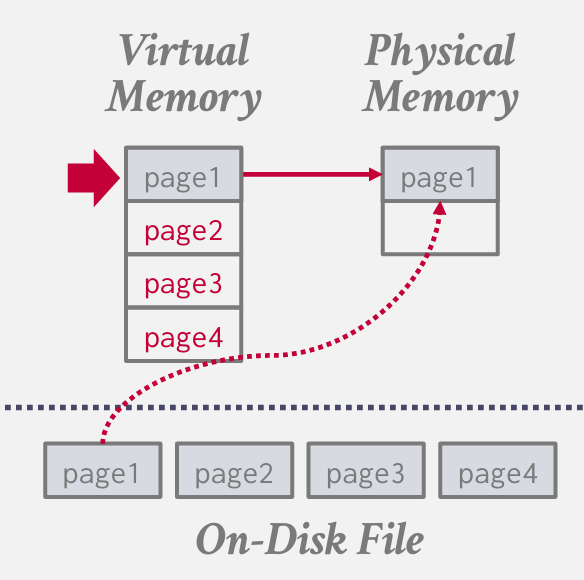
如果我的进程想要访问第一页 我们会遇到页面错误 因为操作系统发现在物理内存中没有找到第一页 然后操作系统会访问磁盘 为我检索数据 将其放入内存 并更新虚拟内存以指向该数据
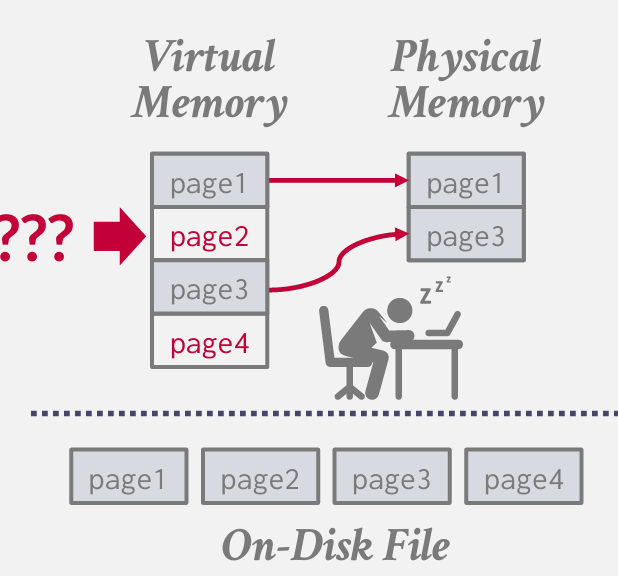
如果想访问page2 -》 my process stalls -- 进程停滞 -- 操作系统发生阻塞 提示 没有更多的物理内存了
but the OS is goint to have its own internal statistics about how these pages are beging accessed. the OS can make a decisoin about what page to evict. -- 问题是操作系统会拥有关于这些页面如果被访问的内部统计数据 并根据数据作出决定 选择那个页面进行置换
but it donesn't know anything about what we're doing inside the database system because it just seeds reads and writes. it doesn't know what's in these data pages, what's in these files.
so the evict, if we rely on the OS, we will face multiple problems. 但它对数据库内部的操作一无所知,因为它仅涉及读取和写入操作 它并不知道查询是什么 不清楚数据页中包含什么内容 也不知道文件中有什么
简单来说就是操作系统并不了解数据库系统内部正在进行的操作;它只知道有读和写的请求发生,但不了解这些数据页面或文件的内容及其重要性。
而这只是一个线程 如果一个线程操作完了 但是另一个线程还想读取这个page 但可能会被驱逐 --我们对操作系统的内部一无所知
如果只读的话 没啥事儿 所以确实一些数据库系统 在系统的只读部分使用了MMAP技术
other problems:
OS can flush dirty pages at any time.
if I have multiple page I need to make sure that these pages are actually written out in the right order and the OS doesn't know. it just solves sees dirty Pages. it doesn't know anything about this page need to be written before.
example if you can lock the page using M lock, but that only prevents the OS from swapping it out doesn't prevent it from writing out, so now it may write out a dirty page.
M-lock 并不会阻止操作系统将脏页写回到磁盘。也就是说,虽然你锁定了页面不让它被换出,但如果你对页面做了修改(使之成为脏页),操作系统仍然可以在任何时间点决定将这些修改后的数据写回到磁盘
脏页就是 更改后未更新到disk中的page
数据写入磁盘的顺序可能至关重要。例如,在事务处理中,必须确保按照一定的顺序提交数据以维护数据一致性。由于操作系统并不了解这种逻辑依赖关系,它可能会根据自己的调度策略异步地写回脏页,这可能导致不期望的数据写入顺序。
- DBMS doesn't know which pages are in memory. The OS will stall a thread on page fault.
- 没法获得错误代码 只能取回中断
有好多系统曾经用过mmap 后来摆脱

顶部的是 完全采用mmap的 下面的是部分采用的 而且有的已经摆脱了
若采用mmap 可以迅速搭建起运行环境 无需自行构建缓冲池管理器 但是需要依赖操作系统来回移动数据 操作系统可能会做出糟糕的意想不到的决策
the problem we need solve
- How the database system represents the database in files on disk
- how the database system manages its memory and moves data back-and-forth from disk.
Disk Layout
数据在磁盘页面上会呈现出三层结构
- File Storage
- Page Layout
Tuple Layout
在文件内部 将会存在page 在page中我们会存在tuple(表中实际数据
暂时先忽略索引 index
File Storage
数据库系统维护一个数据库 作为磁盘上的一个额外文件
SQLite DuckDB 都是单文件数据库 Postgres MySQL 都是多文件数据库
这些文件的格式 是特定的定制格式
so the part of the database system is going to be responsible for maintaining and coordinating these different files is we'll call generically as the storage manager, sometimes it's called the storage engine. 数据库系统中负责维护和协调不同文件的部分 叫 存储管理器 存储引擎
这是系统中与硬件或存储设备通信的组件 无论是引入操作系统还是直接访问 检索数据引入数据库系统的内存中 这些系统中都会维护自己的磁盘调度器或分派器 来决定按某种顺序读取哪些页面 因为我们想最小化 数据载入内存以及立即移出的频繁操作 下节课讲
it organizes the file as a collection of pages, it track what data read or write to pages and track how much space is available in each of them.
A DBMS typically does not . maintain multiple copies of a page on disk.
what is the page?
the page is a fixed-size block of data.
→It can contain tuples, meta-data, indexes, log records…
→Most systems do not mix page types.
→Some systems require a page to be self-contained 意味着 所有该页面内部内容所需要的所有元数据 都应该包含在page中
Each page is given a unique identifier---pageID
→The DBMS uses an indirection layer to map page IDs to physical locations


或许越大越好 因为访存最大化 但越大 写入操作的性能或许也越差 这是需要权衡的一个点
now we will talk about how do we actually keep track of that mapping of page IDs to locations.
现在我们将讨论如何实际跟踪页面ID到位置的映射
Different database systems manage pages in files on disk in different ways.

heap file organization或许是最常见的一种方式
tree file就是 存储在叶节点中 突然想到了merkle tree
也可以使用hash table
ISAM 顺序存储 MySQL曾经默认执行的一种操作
日志结构的相关内容 下节课
heap fine is an unordered collection of pages with tuples that are stored in random order.
数据不必按照精确的顺序指定----但一些系统会进行预排序,来达到一个很好的效果
API: create get write delete iterating all the pages
It is easy to find pages if there is only a single file, like SQLite ....
we just know the page number and size

在sqlite的源文档中,他们在他们的头文件header中,基本上跟踪了所有的元数据来实现这个技巧
if we have many fils, such as postgres, mysql, oracle
page directory
通常是一个特殊文件 要么为了单个数据库文件的头部 要目位于数据库系统内部的某个特殊位置 可以形象的理解为database中的database
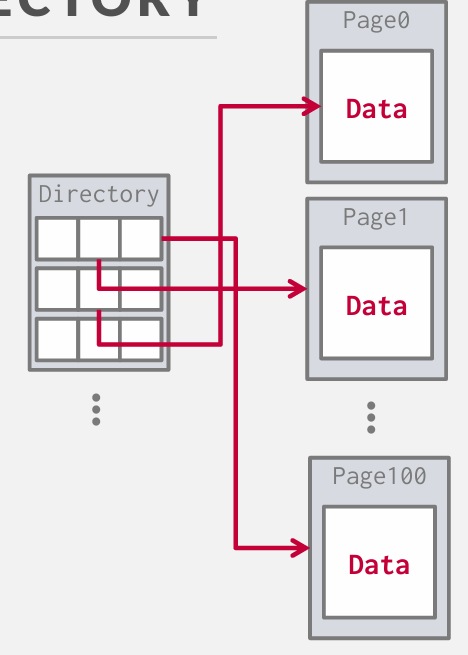
除了物理位置 我们也可以跟踪一些其他额外的元数据 我们可以计入一些关键位置 空槽数量
那么如果我想插入一个元组并且需要找到一个页面来放置它 我不想必须扫描所有页面并计算出那个页面有空闲 page directory会说明这些信息
page layout
every page have header that is going to tell you something about what the data actually is so common thing would be like the page size or a checksum

checksum:如果发生了崩溃 重启了系统 可以快速检查 以确保数据没有被损坏

how to sotre tuples in a page?
let's say we have a really simple approach where in our page header we just keep track of the number of tuples in a page and then just append a new tuple to the end.
so we just go look at the header see the number tuples and multiply that by the size of the tuple that is where offset I want to write the page.
but it's a bad idea
if we have to delete a tuple, then it just throws everything out of order.

if I want to be able to do in insert a new tuple, and we don't want to use the end, we want to use the spot here.

but the tuple is not the fixed length, 这个地方可能放不进去
我们需要额外的源数据来跟踪
如果想把3往上移动 就要告诉系统其他部分 我移动了3这个位置
so the most common layout scheme is called slotted pages(分槽页)
并不是每一个系统都会这样做 但是大多数面向行的数据库系统基本上都会这么做
首先有一个header跟踪数据(前面提到过) 在header 之后 有一个slot array, every position in that slot array is goint to point to some tuple in our page and the tuple begin at the bottom at the end of the page . so in the page bottom we have the fixed length and var-length tuple data.
the slot array storing fixed length offsets to where to find the starting location.
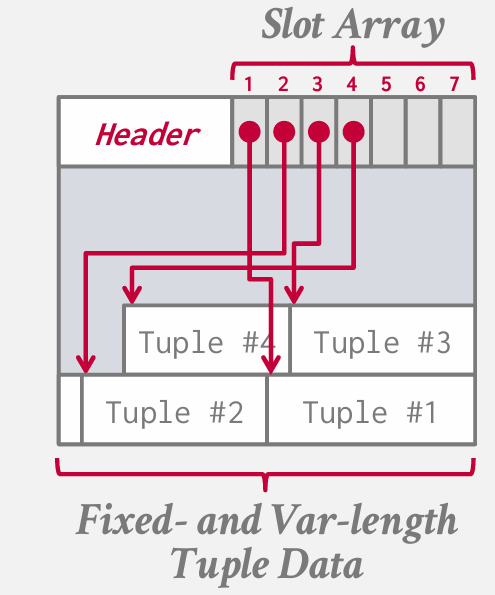
if we want to add tuples, the slot array is going to grow from the begining to the end. and the tuple grow from the end to the beginning.
什么是 page 已满,指的是数据占用了该 page 的一半以上的大小,再也无法存入任何信息了
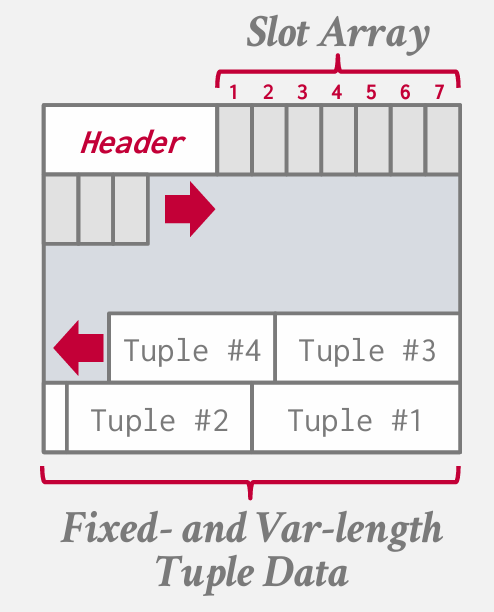
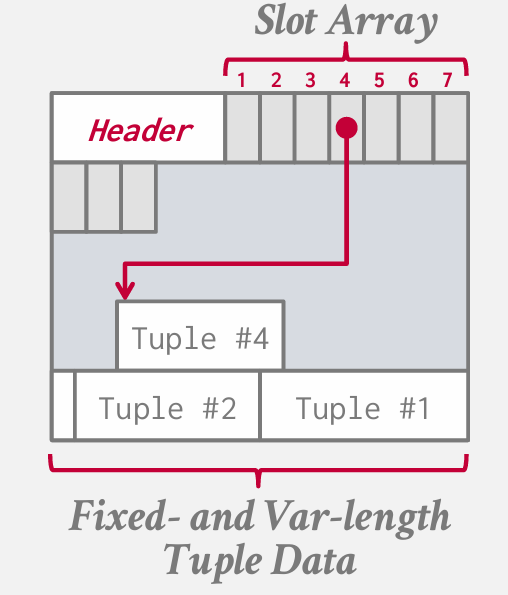
if we delete tuple three.
slot4 还是指向这个地方 我不需要告诉系统的其他地方 移动了4
如果我想移动4过去压缩空间 只需要更新slot array 指向新的偏移量
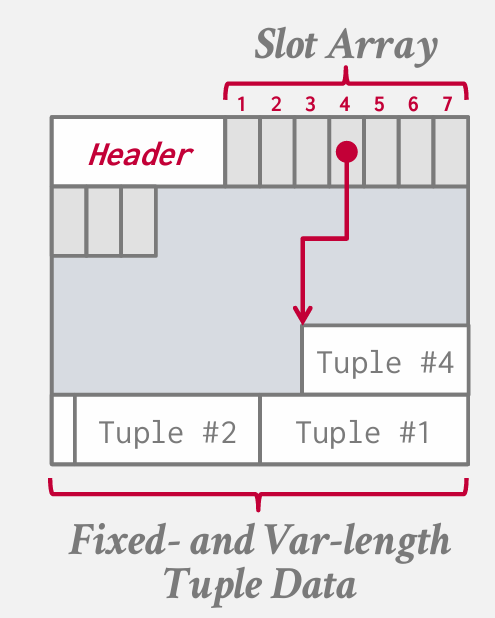
postgres这么做 mysql不这么做 SQLserver这么做
在加入tuple的时候 可能会重新启用slot array3的位置 但是4指向的偏移量不会变 -- 只需要在header里面记录号 tuple5用的slot array3就好了
这样使用可能会浪费一部分空间,比如图中2和3之间有一小块就被浪费了 但是这种方式我们无需调整槽位数组顺序时更新别的内容 足够弥补
一种方法来表示tuple —— record id
不同的数据库可能叫行id 或者是 行号
但是本质上这是一种根据logical tuple 在文件内部 页面内部的物理位置来唯一标识它的方法
通常来说 这是一个 combination of a file number, id number, the page number and then the slot number that corresponds where they exist in that slot array.
所以说如果想要查找 如果有记录id 那么就可以在页目录中找到拥有tuple的页,获取这一页后利用slot array找到该tuple的偏移量
但大多数数据库在tuple 的数据中并没有存储这个id
但是SQLite将此村委一个不应看到的独立列 但是可以访问 他们之所以这么做 是因为他们想以此作为主键 以便能够识别出各个tuple

这都是slot number 就是槽号 不是tuple实际位置 因为是从第四个slot的地方 用指针去找tuple
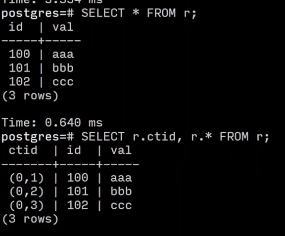
在postgres中有一个ctid的概念
ctid: 表示数据记录的物理行当信息,指的是 一条记录位于哪个数据块的哪个位移上面。
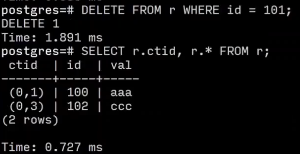
如果我们删除101 我们发现并没有调整其他数据的位置
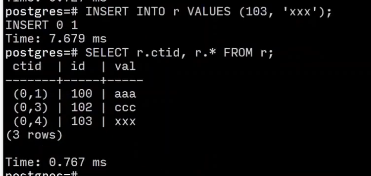
添加后 也没有占用前面的空间
如果启用垃圾回收 在postgres中叫做vacuum,将会压缩每一个页面 写出新的页面 新的文件
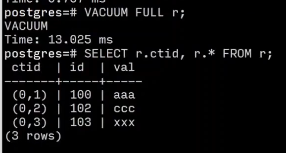
在SQLite中 不会重用行id
在SQL server中
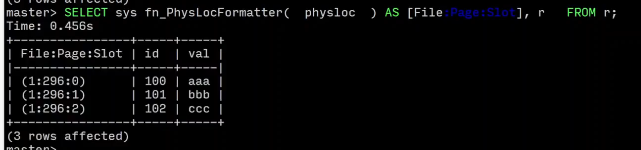
文件编号,页码,槽位编号
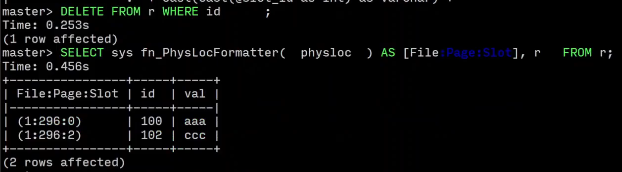
没有移动
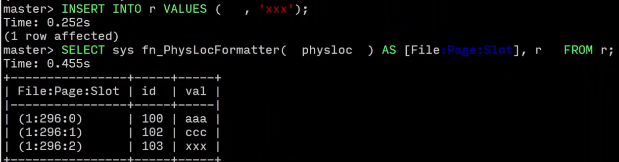
插入新的数据之后 自动移动了
之所以可以这么做 是因为在插入数据的时候 页面被带入内存
当插入tuple的时候,我们持有该页面的锁 数据系统可以决定是否压缩空间 因为他知道没有其他线程可以同时写入该页面
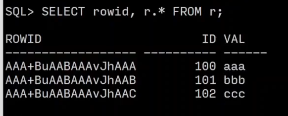
Oracle有rowID
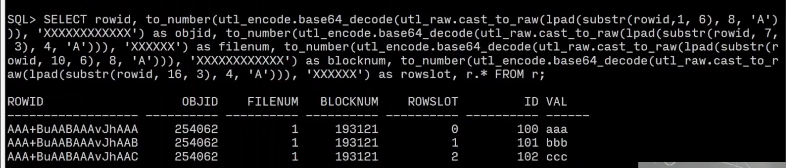
Postgres:
-- create
CREATE TABLE r (
id INTEGER,
val VARCHAR(10)
);
-- insert
INSERT INTO r (id, val) VALUES
(100, 'aaa'),
(101, 'bbb'),
(102, 'ccc');
-- fetch
SELECT r.ctid, r.* FROM r;
DELETE FROM r WHERE id = 101;
-- 再次查询时会看到 (0,1) 和 (0,3) 的 ctid
SELECT r.ctid, r.* FROM r;
VACUUM FULL r;
SELECT r.ctid, r.* FROM r;
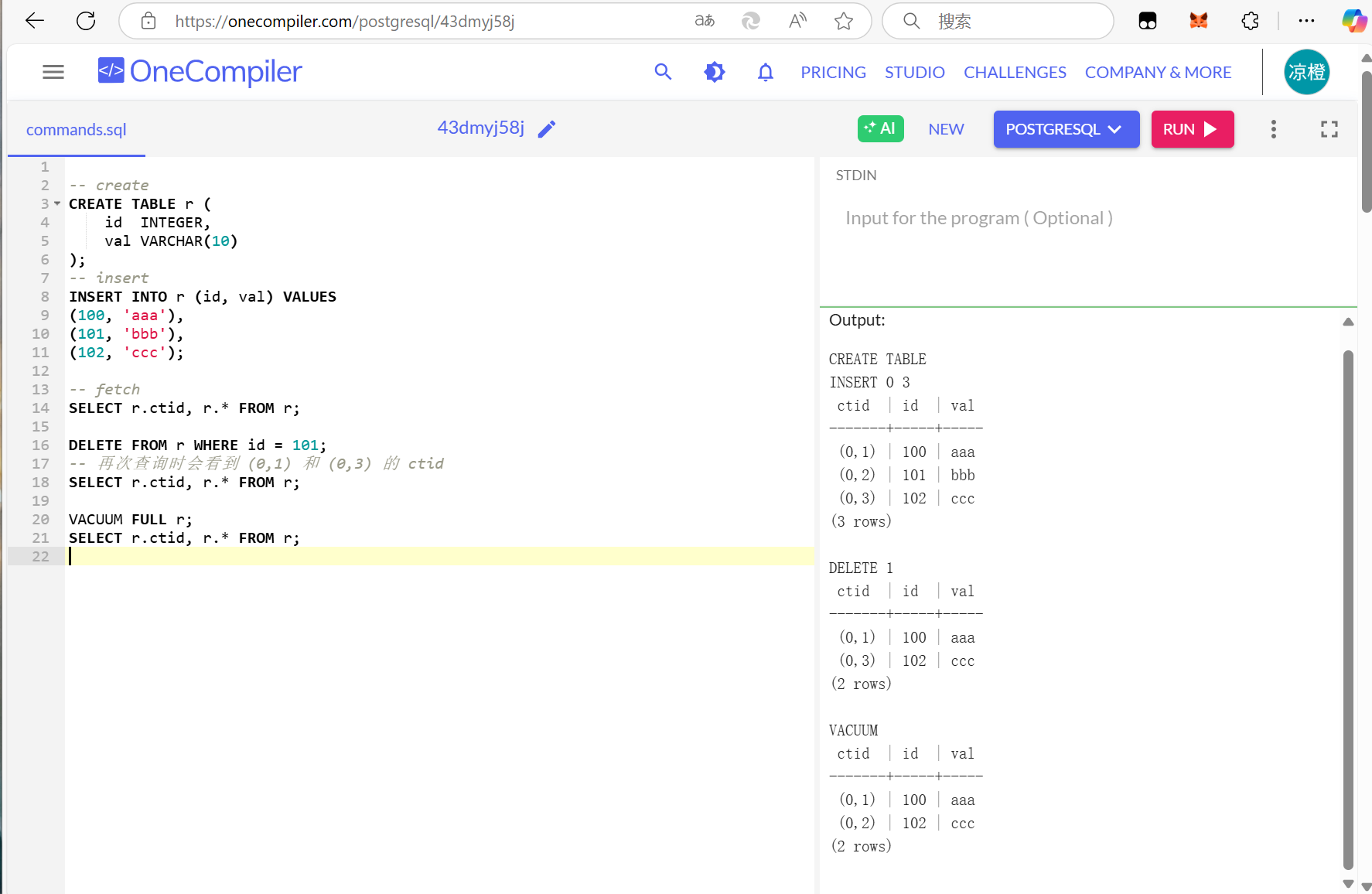
SQLite
-- create
CREATE TABLE r (
id INTEGER,
val VARCHAR(10)
);
-- insert
INSERT INTO r (id, val) VALUES
(100, 'aaa'),
(101, 'bbb'),
(102, 'ccc');
-- fetch
SELECT rowID, r.* FROM r;
DELETE FROM r WHERE id = 101;
SELECT rowID, r.* FROM r;
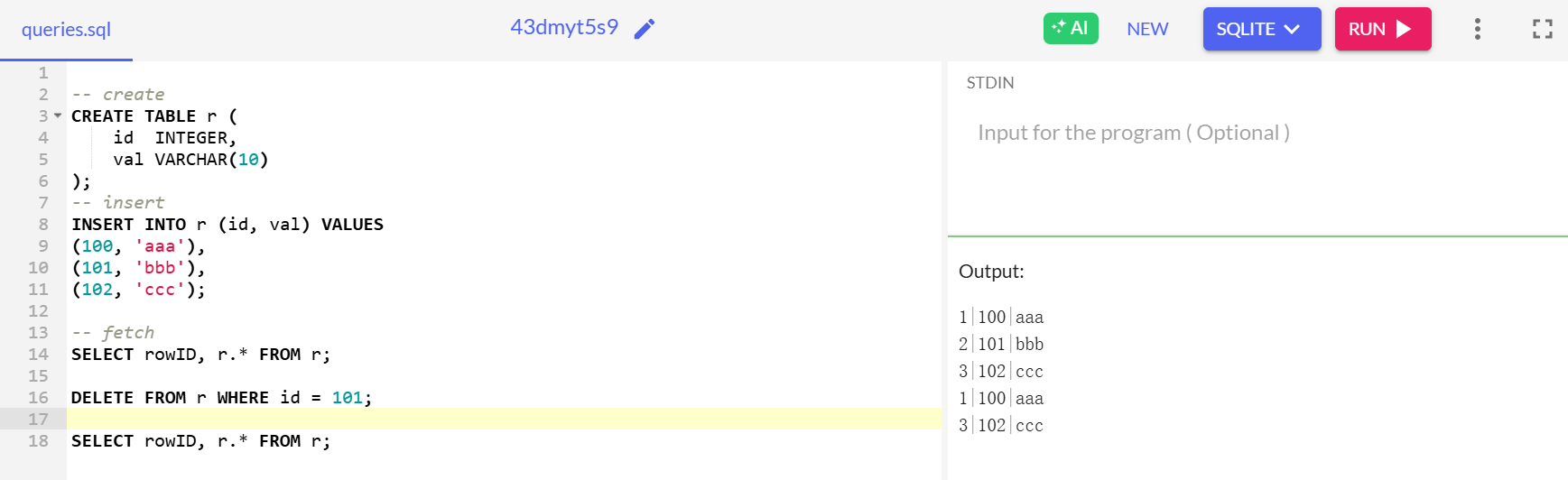
SQL Server
-- create
CREATE TABLE r (
id INTEGER,
val VARCHAR(10)
);
-- insert
INSERT INTO r (id, val) VALUES
(100, 'aaa'),
(101, 'bbb'),
(102, 'ccc');
-- fetch
SELECT
sys.fn_PhysLocFormatter(%%physloc%%) AS [File:Page:Slot],r.*
FROM r;
DELETE FROM r WHERE id = 101;
SELECT
sys.fn_PhysLocFormatter(%%physloc%%) AS [File:Page:Slot],r.*
FROM r;
INSERT INTO r values (999,'xxx');
SELECT
sys.fn_PhysLocFormatter(%%physloc%%) AS [File:Page:Slot],r.*
FROM r;
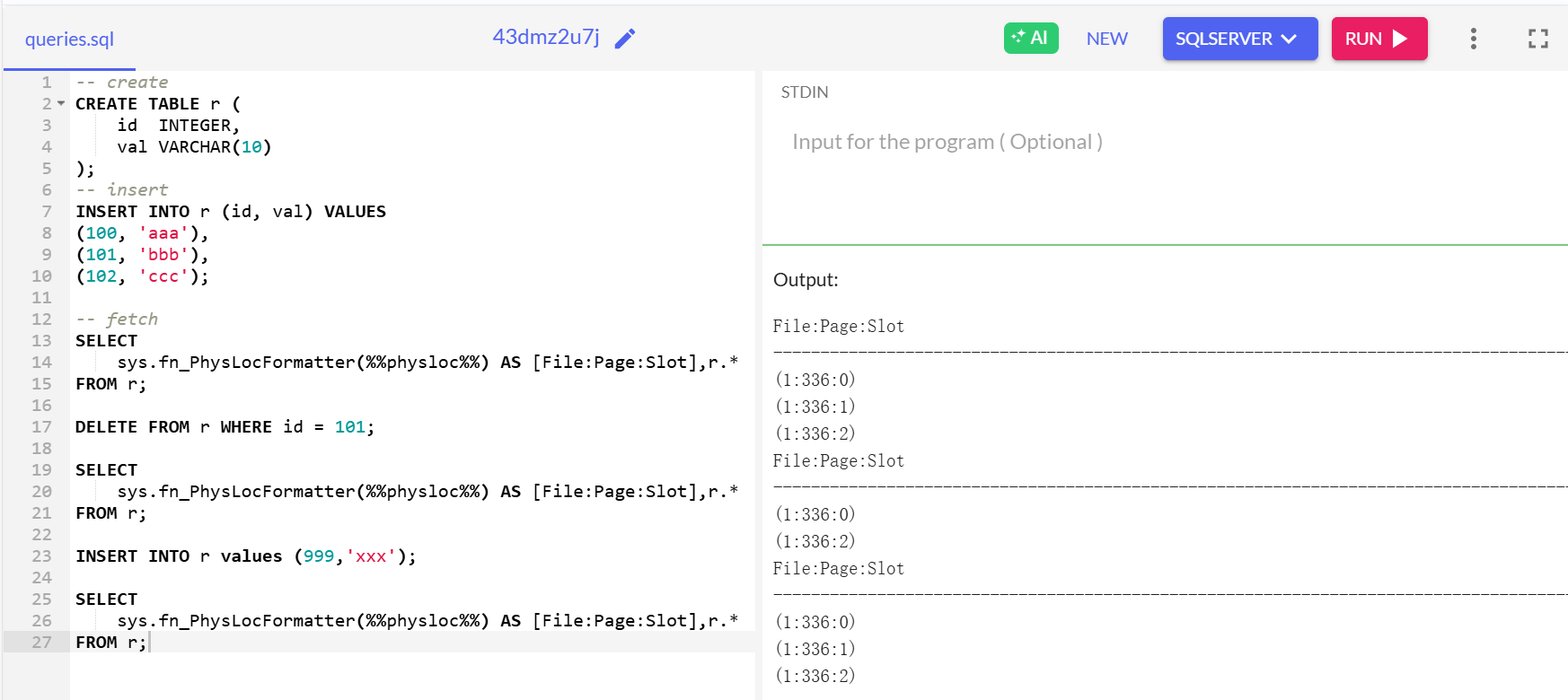
Oracle
Oracle 的 ROWID 是 18 位字符,格式为:
OOOOOOFFFBBBBBBRRR
- OOOOOO:数据对象号(Data Object Number)
- FFF:文件号(File ID)
- BBBBBB:块号(Block Number)
- RRR:行号(Row Number,即块内偏移量,从 0 开始)
-- create
CREATE TABLE r (
id INTEGER,
val VARCHAR(10)
);
-- insert
INSERT INTO r (id, val) VALUES
(100, 'aaa'),
(101, 'bbb'),
(102, 'ccc');
-- fetch
SELECT rowid, r.* FROM r;
DELETE FROM r WHERE id = 101;
SELECT rowid, r.* FROM r;
INSERT INTO r (id, val) VALUES (999,'zzz');
SELECT rowid, r.* FROM r;
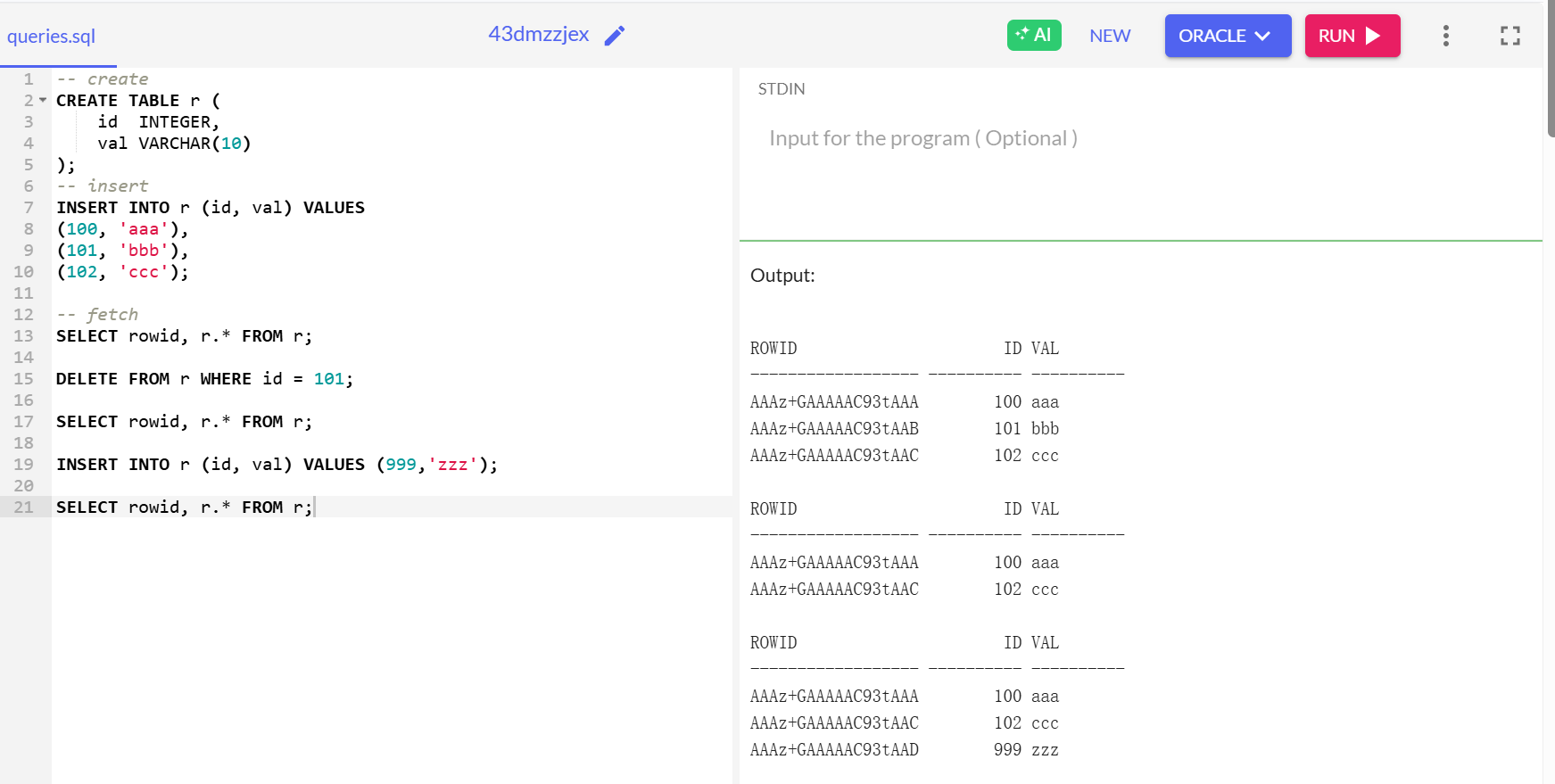
tuple layout
tuple 本身只是一串字节序列
database system to know how to interpret those bytes based on the type and based on the values that you're looking at.

tuple 有一个 header 存储自己本身的一些元数据
因此会有可见性信息 -- 比如这个元组是否被删除
用bitmap(位图)表示null 后面会讲
Attributes are typically stored in the order that you specify them when you create the table.
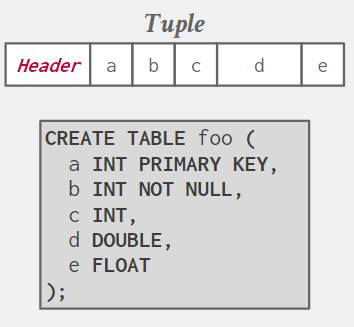
这样做是出于software engineering reasons(软件工程原因) -- simplicity 更简单
但是,以不同的方式布局它们可能更有效
如果我有两个表 其中一个表中有外键引用另一个表
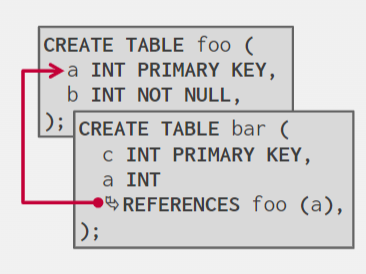
查询的时候可能需要连表
SELECT * FROM foo JOIN bar ON foo.a = bar.a;
我可以存储为单独的页面
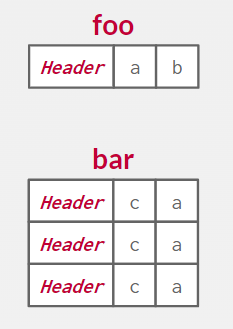
但是有些系统将相关表的元组嵌入在 原始的基本元组中
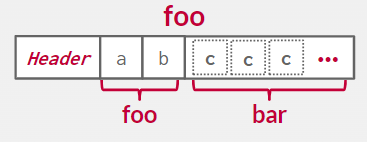
在应用程序中 它仍然看起来是两个单独的表 但在幕后 我可以嵌入他们可以使事情更快
但是这样对应的更新也会more expensive 性能更差